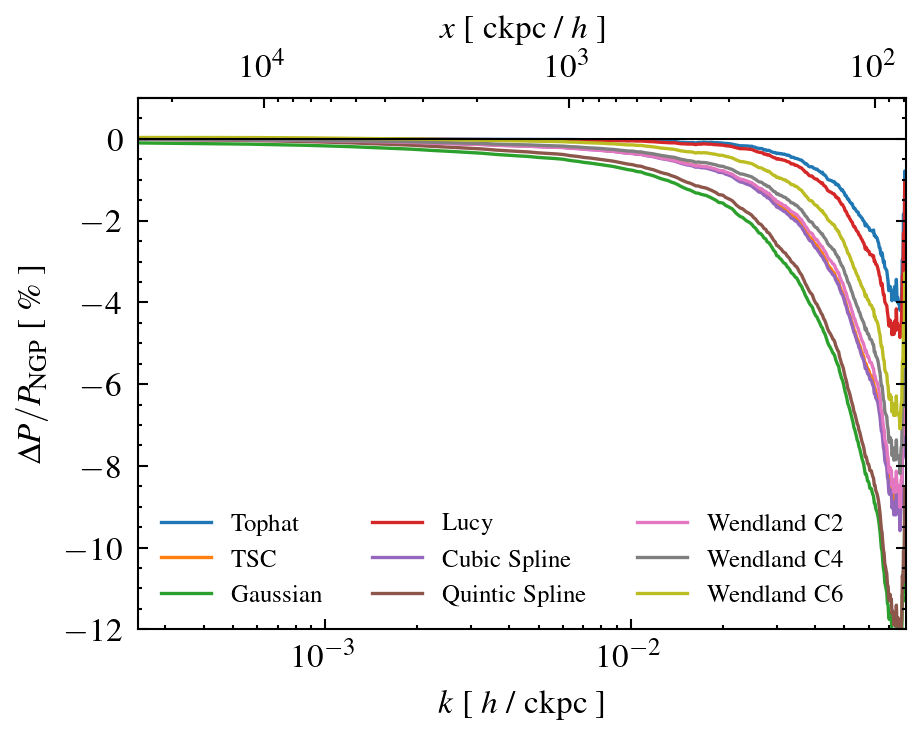Exploring kernel functions¶
In this tutorial we will see all kernel functions currently available in smudgy.
We will deposit a particle dataset from a cosmological N-body simulation with different kernels and investigate the advantages of certain kernels wrt. dynamic range and power spectrum analysis.
First, let’s load all necessary packages and modules.
import numpy as np
import matplotlib.gridspec as gridspec
import matplotlib.pyplot as plt
import smudgy as sm
from smudgy import get_kernel_shapes_1D
from powerbox import get_power
As discussed in the Kernels and Structures wiki page, smudgy supports separable, iso- and anisotropic structures. Currently, only tophat, tsc and gaussian kernels can be used for separable structures, while all kernels can be used for the other two.
Let’s define the structures and a dict with kernel names to analyze.
structures = ['separable', 'isotropic', 'anisotropic']
kernel_names = {
"Tophat": "tophat",
"TSC": "tsc",
"Gaussian": "gaussian",
"Lucy": "lucy",
"Cubic Spline": "cubic_spline",
"Quintic Spline": "quintic_spline",
"Wendland C2": "wendland_c2",
"Wendland C4": "wendland_c4",
"Wendland C6": "wendland_c6",
}
batch_1 = {name: kernel_names[name] for name in list(kernel_names.keys())[0:3]}
batch_2 = {name: kernel_names[name] for name in list(kernel_names.keys())[3:6]}
batch_3 = {name: kernel_names[name] for name in list(kernel_names.keys())[6:9]}
batches = [batch_1, batch_2, batch_3]
colors = plt.rcParams['axes.prop_cycle'].by_key()['color'][:len(kernel_names.keys())]
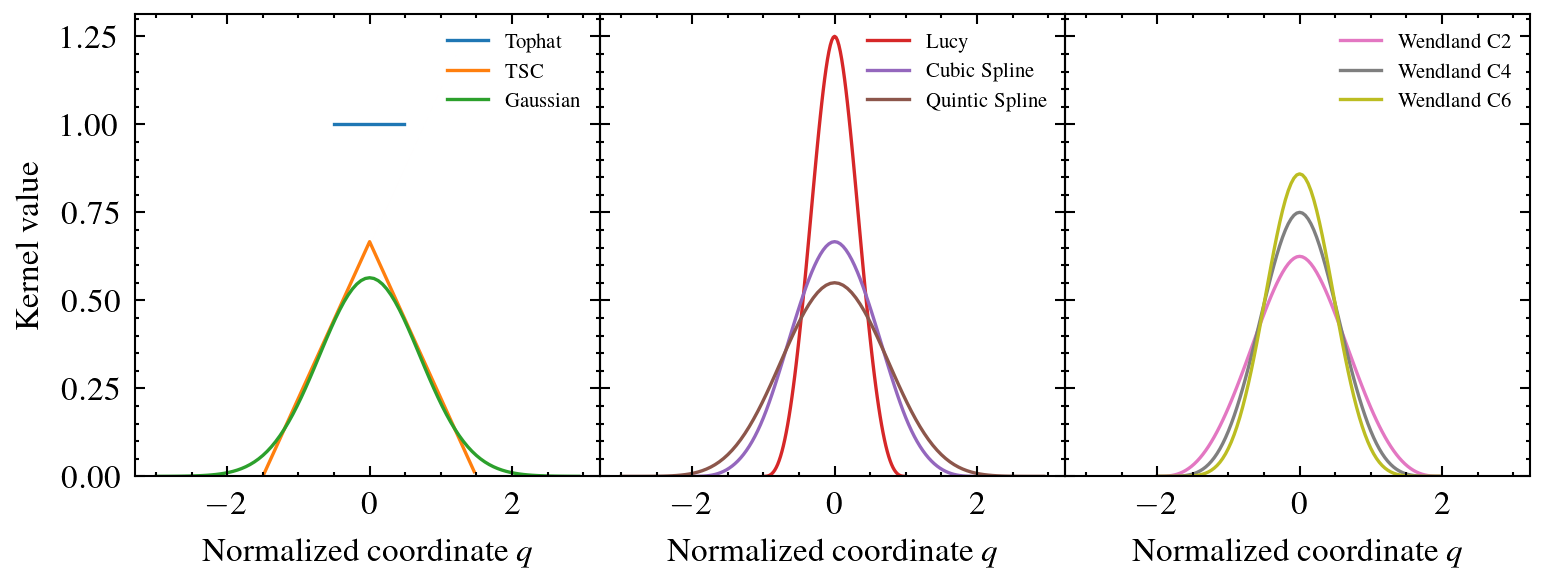
Kernel shape comparison¶
The following figure shows a comparison of all available 1D kernel functions in smudgy, where the normalized coordinate \(q=|r|/h\).
Effect of kernel shape on Power Spectrum¶
Different kernels are defined over different support domains. Some kernels exhibit sharper and more concentrated shapes, while others are more smoothly extended. Therefore, interpolation and deposition results almost always depend on the chosen kernel. We demonstrate this in the following workflow, where we deposit particles from a cosmological N-body simulation using different kernel functions.
First, we compute a reference grid using Nearest Grid Point assignment (NGP), which is often used in such applications. Then, with NGP as the baseline we compare the results by using higher order kernels and finally show the relative difference on the power spectrum.
We use the TNG50-4-Dark simulation from the publically available TNG runs as well as the illustris_python package to load positions, masses and the boxsize information.
Then we initialize a PointCloud object, set some parameters to use during later computations and compute the smoothing lengths. For this tutorial we use isotropic structures.
cloud = sm.PointCloud(
positions=positions,
weights=masses,
boxsize=boxsize
)
gridnums = 512
num_neighbors = 16
kwargs = dict(
fields=cloud.weights,
averaged=False,
gridnums=gridnums,
eta_crit=10, # due to anti-aliasing for tophat kernel
omp_threads=10,
)
cloud.global_setup(num_neighbors=num_neighbors, structure='isotropic')
cloud.compute_smoothing()
[smudgy] Initialized 3d PointCloud with 19683000 particles in periodic box of size=[35000 35000 35000]
[smudgy] Set structure globally to 'isotropic'
[smudgy] Set number of neighbors globally to 16
[smudgy] Building kd-tree from particle positions
[smudgy] Computing smoothing lengths from 16 neighbors
Next we compute the reference grid using NGP and perform the depositions by looping over the different kernels.
f_ref = cloud.deposit_to_grid(
**kwargs,
kernel_name='ngp',
)[..., 0]
maps = []
for kernel_name, kernel_key in kernel_names.items():
f = cloud.deposit_to_grid(
**kwargs,
kernel_name=kernel_key,
)[..., 0]
maps.append(f)
[smudgy] Using c++ backend for ngp deposition (ngp_3d)
[smudgy] Using c++ backend for isotropic deposition (isotropic_3d)
[smudgy] Using c++ backend for isotropic deposition (isotropic_3d)
[smudgy] Using c++ backend for isotropic deposition (isotropic_3d)
[smudgy] Using c++ backend for isotropic deposition (isotropic_3d)
[smudgy] Using c++ backend for isotropic deposition (isotropic_3d)
[smudgy] Using c++ backend for isotropic deposition (isotropic_3d)
[smudgy] Using c++ backend for isotropic deposition (isotropic_3d)
[smudgy] Using c++ backend for isotropic deposition (isotropic_3d)
[smudgy] Using c++ backend for isotropic deposition (isotropic_3d)
The figure below offers a visual comparison between the different maps.

Next, we use the get_power function from the powerbox package to compute power spectra for the baseline and kernel maps.
pk_ref, k_ref = get_power(f_ref, boxlength=boxsize)
power_spectra = []
for f in maps:
p, k = get_power(f, boxlength=boxsize)
power_spectra.append(p)
Finally we compare the power spectra wrt. the baseline (NGP). For the chosen deposition parameters, we see that different kernels can have a relatively large impact (order percentage) especially on scales \(x \leq 1 \, \mathrm{cMpc}/h\)